Monitoring#
Recent advancements in NLP and the rise of LLMs have accelerated the usage and adoption of textual data in ML applications in the mainstream, making it a commodity. Sentiment analysis, text summarization, question answering, text classification, translation, and so forth are only a small sampling of the possible use cases we are seeing come to life.
But as with any ML model, developing and deploying a model is only the first phase of its MLOps lifecycle. We need to be able to monitor it, maintain it, and ensure we have all the required governance tools and practices in place to avoid unnecessary business damage or risk. However, with deep learning models, monitoring is harder than with its supervised counterparts as there are no clear, meaningful structured inputs we can monitor to detect potential drift or data quality issues in the deep learning embedding space.
Elemeta provides data scientists with an elegant way to extract meaningful information and properties out of a potential input text used by your model that can be monitored and tracked to detect ongoing issues in an interpretable fashion. In this example, we will use Elemeta together with Superwise’s model observability community edition to supply visibility and monitoring of your NLP model’s input text.
Walkthrough#
Sign in to your Superwise community account (or signup if you don’t have one).
Build your first project and upload your first model (see the quickstart guide).
Start sending ongoing predictions and inputs together with their Elemeta metafeatures.
Production_data # the production data Dataframe # Extract metafeature values using MetafeatureExtractorsRunner metafeature_extractors_runner = MetafeatureExtractorsRunner() production_data_with_metafeatures = metafeature_extractors_runner.run_on_dataframe(dataframe=production_data,text_column='content') #send the data to superwise transaction_id = sw.transaction.log_records( model_id=1, version_id=1, records=production_data_with_metafeatures.to_dict(orient="records") )
Visualize and observe your text input properties and statistical behavior and put policies in place to alert on any change.
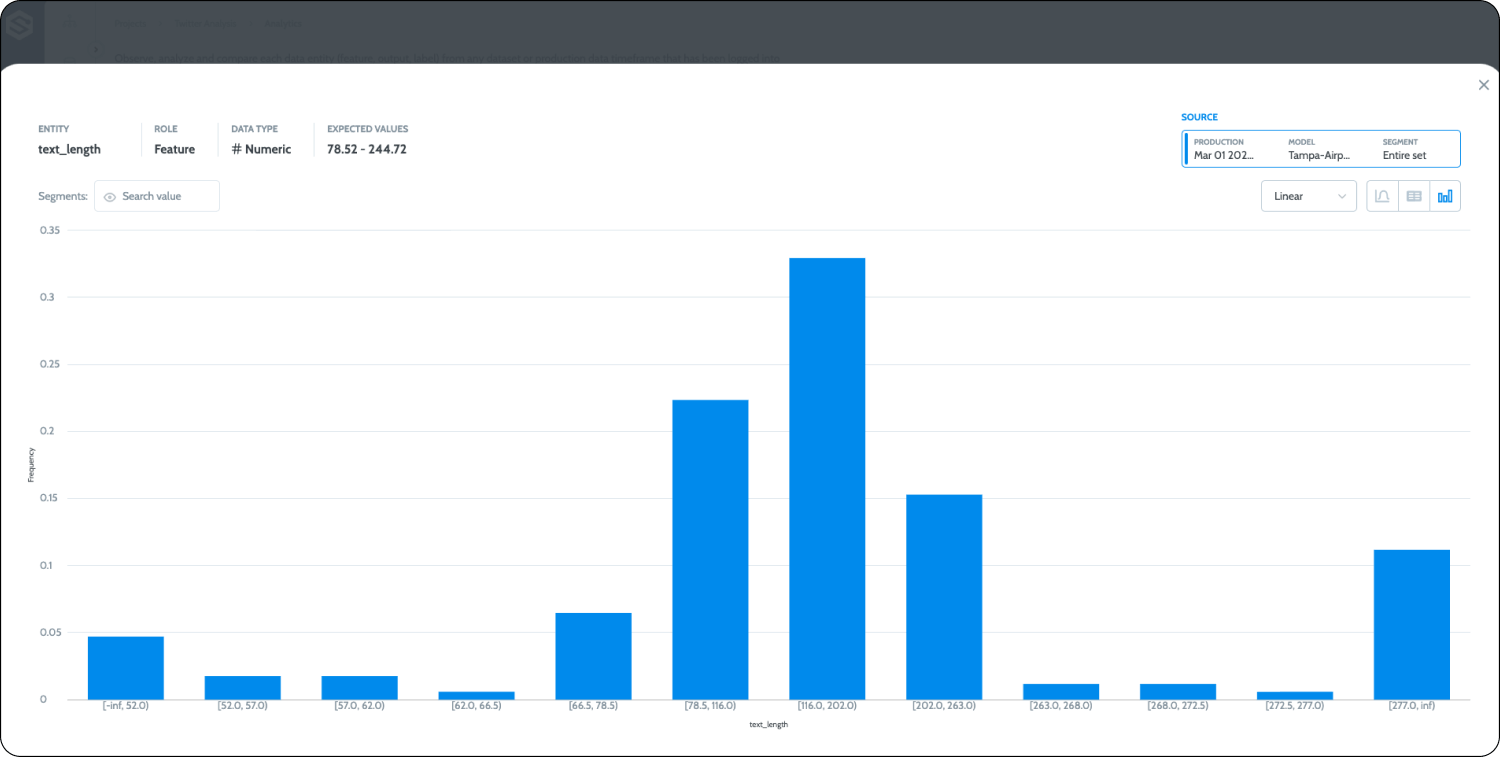
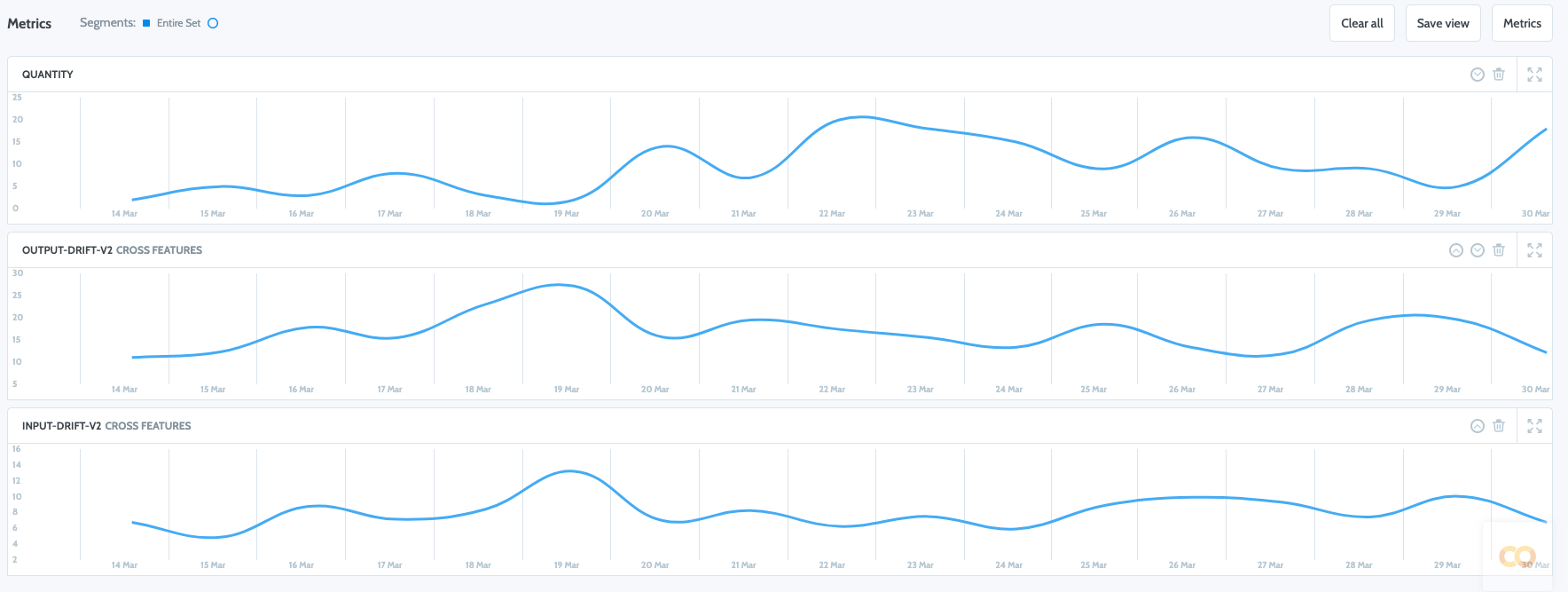
For a full working example please use the following Google Colab